PyTorch 實戰 - 高鐵驗證碼辨識
Introduction
A CAPTCHA (/kæp.tʃə/, an acronym for “completely automated public Turing test to tell computers and humans apart”) is a type of challenge–response test used in computing to determine whether or not the user is human.
The term was coined in 2003 by Luis von Ahn, Manuel Blum, Nicholas J. Hopper, and John Langford. The most common type of CAPTCHA (displayed as Version 1.0) was first invented in 1997 by two groups working in parallel. This form of CAPTCHA requires that the user type the letters of a distorted image, sometimes with the addition of an obscured sequence of letters or digits that appears on the screen. Because the test is administered by a computer, in contrast to the standard Turing test that is administered by a human, a CAPTCHA is sometimes described as a reverse Turing test.
Wikipedia ── CAPTCHA
驗證碼的主要目的在於辨別人類與電腦,目前主流為圖形文字認證,也就是顯示一張背景干擾、文字扭曲的英數圖片,要求使用者填入圖片中的文字,並在比對確認無誤後才可進行接下來的操作(如留言、交易等)。在過往,由於影像的破損,使電腦因為無法從背景的雜訊中讀出這些字母而難以辨識,但受惠於硬體效能的提升與深度學習的崛起,使電腦得以透過機器學習來辨識驗證碼影像並帶有高準確率。目前主流的機器學習庫包含 PyTorch、Tensorflow(with Keras)等,在本文中,我們選擇 PyTorch 作為使用的機器學習庫,並以此建立一神經網路對台灣高鐵網站上的驗證碼進行訓練與辨識。
在開始前,我們先分別以字元與影響兩個方向對高鐵驗證碼進行觀察與分析:
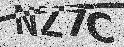
字元(Character)
在字元上,驗證碼主要由四個包括大寫英文與數字所組合,直覺上我們可以將影像切割為四張影像分別進行辨識,然而當影像大小或字元位置不一時,切割後所產生的些許誤差將會造成錯誤率的攀升,因此我們選擇直接以整張影像進行訓練,並在 Dropout 後接上四個 Linear 進行輸出。影像分割(Segmentation):
影像分割的好處在於能夠降低神經網路的複雜度,使我們能使用更簡單的架構來訓練並降低訓練所需的時間,同時在資料集不變的情況下增加可訓練的素材。舉例而言,當驗證碼為四碼時,同一張影像樣本若進行分割即可變為四個影像樣本。影像(Image)
在影像上,除了本身的字元外,還包含了背景的雜訊與一條與字等粗的弧線。為了使訓練更有效率並提高準確率,在訓練前我們需要先將影像先進行預處理,分別是濾雜訊與除弧線。
Image Pre-processing
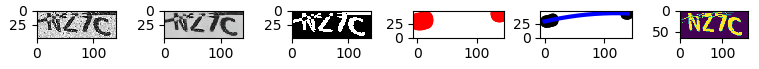
在影像預處理中,我們將會對原始驗證碼影像依序進行:
- 濾雜訊(Denoise)
- 去弧線(Remove Curve)
- 二值化(Binarization)
- 線性回歸(Linear Regression)
- 疊加(Add)
Denoise
在濾雜訊的部分上,我們除了可以透過中值濾波器(Median Filter)來濾雜訊外,也可以簡單地透過 OpenCV 所提供的 fastNlMeansDenoisingColored 函式完成。
首先先安裝 OpenCV for Python:
1 | $ pip3 install opencv-python |
接著透過 OpenCV 讀檔並先將影像調整至固定大小後再進行濾雜訊:
1 | import cv2 |
Remove Curve
由於驗證碼中的弧線可以以一個二項式迴歸公式表示,因此我們便可以使用 sklearn 的 linear model 來繪出適合的弧線,並疊加至驗證碼影像上將弧線去除。
首先,我們先將影像進行二值化後轉為灰階陣列,並建立一影像副本 image_copy 供後續操作:
1 | ret, thresh = cv2.threshold(dst, 127, 255, cv2.THRESH_BINARY_INV) |
接著,將影像副本中間有字的部分挖空,僅留下線條的前段與後段:
1 | image_copy[:, 15:width-5] = 0 |
之後我們便可以透過線性回歸來繪出弧線,並將弧線疊加至原始影像上完成去弧線:
1 | x1_s = np.array([axis_x]) |
PyTorch
PyTorch is an open source machine learning library based on the Torch library, used for applications such as computer vision and natural language processing. It is primarily developed by Facebook’s artificial intelligence research group. It is free and open-source software released under the Modified BSD license. Although the Python interface is more polished and the primary focus of development, PyTorch also has a C++ frontend. Furthermore, Uber’s Pyro probabilistic programming language software uses PyTorch as a backend.
PyTorch provides two high-level features:
- Tensor computing (like NumPy) with strong acceleration via graphics processing units (GPU)
- Deep neural networks built on a tape-based autodiff system
Wikipedia ── PyTorch
Networks
在對驗證碼影像做預處理後,我們便可以開始對神經網路進行訓練,在本篇文章中使用基本卷積神經網路(ConvNets, CNNs),其中包含了五層網路層(Layer)與一層全連接層(Fully Connected)。
1 | ConvNets( |
為了使神經網路得以加深以及避免 Overfitting,我們在第三層與第五層中加入正規化(Batch Normalization)並於全連接層(Fully Connected)中放棄 50% 神經元。
Training
OneHot
在訓練神經網路時,通常會使用 OneHot Encoding 來提升其收斂速度並提高準確率。OneHot Encoding 指的是在訓練時,將正確的類別(該對應到的項目)設定為 1,反之則設定為 0。
舉例而言,在一手寫數字識別的神經網路中,資料集包含一張影像:

若對此影像進行 OneHot Encoding,我們將得到:
1 | # Source Number: 0 1 2 3 4 5 6 7 8 9 |
在了解 OneHot Encoding 後,我們觀察高鐵驗證碼,可以發現驗證碼字元是由 6 個數字與 13 個英文字母所組成,其中英文字母不區分大小寫,因此我們可以建立驗證碼字典為:
1 | CAPTCHA_DICT = ['2', '3', '4', '5', '7', '9', 'a', 'c', 'f', 'h', 'k', 'm', 'n', 'p', 'q', 'r', 't', 'y', 'z'] |
由於驗證碼有四個字元,因此若將驗證碼進行 OneHot Encoding,我們將得到:
1 | onehot_result = [ |
當然我們不可能對每張圖片都手動建立 OneHot Encoding Result 除非你很閒,因此可以將這部分寫成函式:
1 | def encoding(self, label): |
Image Label
在標籤資料集上有兩種比較常見的做法,其一是手動對每張影像進行標籤,其二則是找出影像產生規則後,以程式產生並進行訓練。在本篇文章中採用第一種,也就是手動對每張影像進行標籤。
理論上資料集越龐大,訓練出來的神經網路準確率會越高。但為了偷懶減少需要標籤的影像,我們先標籤少量影像,並在神經網路的準確率達到一定後透過程式增加資料集。
首先我們先從高鐵網站上擷取 1000 張驗證碼影像後,對每一張進行標籤,其中 500 張做訓練集,另外 500 張做測試集。訓練次數與其準確率如圖:
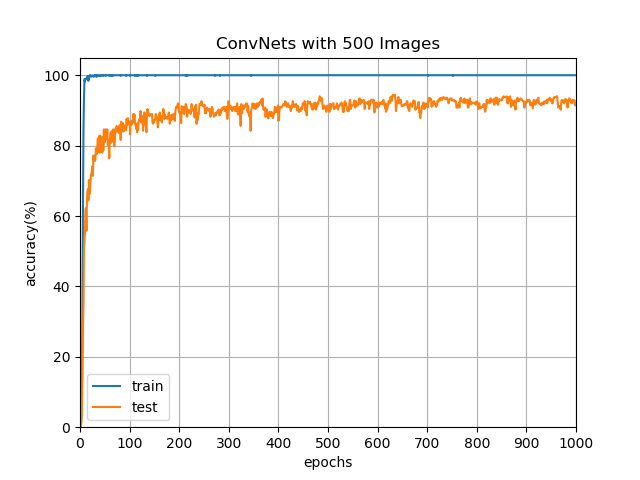
從圖中我們可看出在訓練超過 20 次之後神經網路準確率可達到七成以上,40 次後準確率更可達到八成左右,在一般使用上已在可接受的範圍。雖然可以通過繼續訓練神經網路以得到更高的準確率,但受限於資料集的數量,準確率的成長幅度將愈趨平緩。
或許你會有個疑問是,既然 500 張影像可以透過多次訓練來提高準確率,那更少的影像是不是可以透過更多次的訓練來達到相同的準確率?我們直接以 250/250 張的資料集來進行測試,其最高準確率為 50.8%:
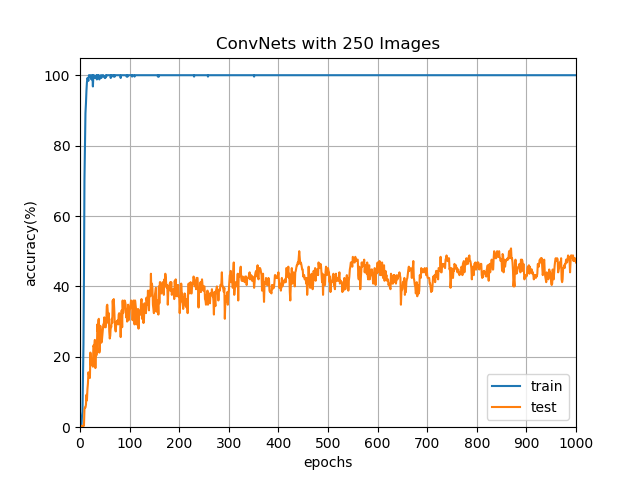
從實驗結果可以很明顯看出,若是想更進一步提升準確率,則必須增加訓練用的資料集。既然已經有訓練好且準確率可達八成以上的神經網路,我們便可以透過使用 Selenium,由高鐵訂票網站上抓取驗證碼,以訓練好的神經網路進行辨識後,填入查詢表單並送出來檢測驗證碼是否正確,若正確則儲存驗證碼影像與標籤,反之則略過。為了降低伺服器的負擔,我們必須在 WebDriver 上設定適當的延遲。
透過這種方式,我們將資料集增加至 20000 張,分別為 10000 張的訓練集與 10000 張的測試集。訓練次數與其準確率如圖:
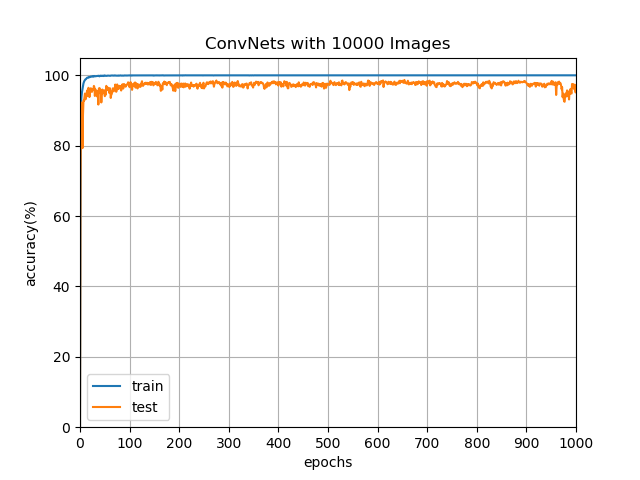
由於資料集的充足,使得網路在經過三次訓練後可達到 92.23% 的準確率,透過增加訓練次數以及花費 3d12h21m13s984ms 的時間,準確率最高更可達到 98.66%。
Conclusion and Suggestions
在本文中,成功以基礎卷積神經網路對高鐵驗證碼進行辨識並達到 98.66% 的準確率。一般而言,若是為了達到九成以上的準確率,以訓練資料集 10000 張而言大約需要訓練 10 次即可。耗時由於根據電腦硬體規格會有不同的數值,以本文所使用之電腦規格為例:
| Item | Content |
|---|---|
| CPU | AMD Ryzen 7 1700 8C/16T 3.00 GHz |
| RAM | DDR4 2133 16GB *2 |
| VGA | NVIDIA GeForce GTX 750 |
| SSD | Micron MX500 500GB |
我們分別對其進行一次 10000/10000 資料集的訓練與測試,數據如下表:
| Type | Training | Testing |
|---|---|---|
| CPU | 40m16s892ms | 14m34s601ms |
| GPU | 4m16s643ms | 0m59s138ms |
可以看出即便是中階顯卡,在神經網路訓練的計算優勢上仍遠大幅高於 CPU,因此建議在訓練神經網路時以顯示卡進行運算,可以節省相當多時間。
此外,除了基本卷積神經網路,使用者亦可以嘗試以其他神經網路進行訓練,例如近年來熱門的深度殘差網路(Deep Residual Network),或許可以得到更高的準確率。
Remarks
2022-07-21 updates
驗證碼不知道在什麼時候開始有增加字元集,導致原本的辨識率大幅降低,目前確認的字元為:1
CAPTCHA_DICT = ['2', '3', '4', '5', '6', '7', '8', '9', 'A', 'C', 'D', 'E', 'F', 'G', 'H', 'K', 'M', 'N', 'P', 'Q', 'R', 'T', 'V', 'W', 'Y', 'Z']